Compiler Design and Construction Question Bank Solution 2081
Explore comprehensive solutions to Compiler Design and Construction questions, updated for the year 2081. Customize this content for different subjects and years to enhance your SEO.
Define Syntax directed definition. Construct annotated parse tree for the input expression (5*3+2)*5 according to the following
syntax directed definition.

syntax directed definition.
SDD i.e Syntax Directed Defination is a formal way to specify the syntax and symantic of a programming language. It is a context-free grammar togetherwith attributes and rules.
for eg:
| Production | Semantic Rules |
| E → T | E.val = T.val |
| T → T1 * F | T.val = T1.val * F.val |
The annoted parse trees for input expression:
(5*3+2)*5

fig : Annoted parse tree for expression (5*3+2)*5
Difference between compiler and interpreter. “Symbol table is necessary component of compiler”. Justify this statement with examples.
Difference between compiler and interpreter.
| Features | Compiler | Interpreter |
| Translation | Translates entire source code into machine code at once. | Translates source code line by line during execution. |
| Output | Generates executable file or machine code | Doesn,t produce a separate executable file. |
| Execution Speed | Generally produces faster execution of code. | May have slower execution due to real time translation. |
| Error Detection | May detect error during compilation. | Detects error during interpretation often as encountered. |
| Memory Usage | Typically requires more memory during compilation. | Require less memory during execution. |
| Portability | Compiled code may not be portable across platforms. | Interpreted code is usually more portable. |
| Debugging | Debugging may be more complex due to machine code. | Easier debugging as error are encountered in the source. |
A symbol table is crucial for a compiler because it helps to keep track of information about variables, functions, and other identifiors in a program. This is essential for the compiler to correctly analyze and generate code.
some simplified reasons with eg:
a. Tracking variables and their scopes : The symbol table helps the compiler know which variables are in scope and accessible at any point in program.
eg:
void scope()
{
int x = 10;
{
int x = 20;
printf("%d",x);
}
printf("%d",x);
}
b. Type checking : The symbol table helps ensure that operations on variables are performed correctly according to their types.
eg:
int a = 2; float b = 3.5; a = a+b; // Error : adding float to int without conversion
c. Memory allocation : The symbol table that compiler allocate memory for variables.
eg:
int num; char letter; float amount;
d. Function information : The symbol table stores details about functions such as their return types and parameters.
eg:
int add(int x, int y)
{
return x+y;
}
int main()
{
int result = add(2, 3);
printf("%d", result);
}
e. Name Resoulation : The symbol table helps resolve which variable or function an identifier refers to.
eg:
int value = 10;
int get value()
{
return value;
}
List out the major tasks carried out in Lexical Analysis Phase. Convert the following NFA to DFA.
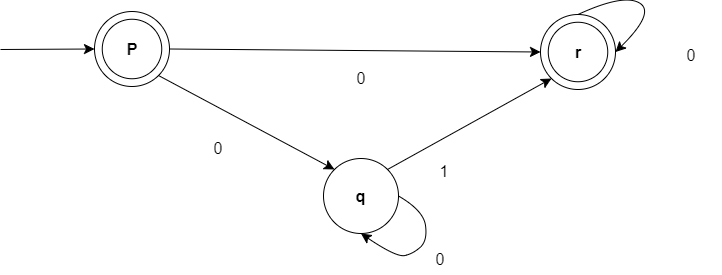
The lexical analysis phase, also known as scanning or tokenization is the first phase of a compiler. During this phase, the sourse code is processed to convert it into a sequence of tokens.
Here, are the major tasks carried out in the lexical analysis phase.
a. Reading Input Characters : The lexical analyzer reads the input characters from source code sequentially.
b. Removing whitespace and comments : Whitespace and comments are removed as they are not needed foe further analysis.
c. Token Generation : Characters are grouped into meaningful sequences called tokens.
d. Lexeme Recognition : Specific sequences of characters or lexemes are recognized according to token patterns.
e. Token classification: Each lexeme is classified into a token type such as keyword, identifier, operator etc.
f. Error handling: The lexical analyzer detects and reports invalid tokens or characters.
solution
| States | Next | state |
| 0 | 1 | |
| →* {p} | {r,q} | Φ |
| * {r,q} | {r,q} | {r} |
| * {r} | {r} | Φ |
| Φ | Φ | Φ |
Transition diagram for above table

Differentiate between recursive descent and non-recursive predictive parsing method. Find first and follow of all the non-terminals in the following grammar.
E→TA; A→ +TA|ε ; T→FB; B→*FB|ε ; F→(E)|id
Difference between recursive descent and non-recursive predictive parsing method:
| Feature | Recursive Descent Parsing | Non-recursive predictive parsing |
| Defination | User recursive function for each non-terminal. | Uses a stack and parsing table to predict and parse. |
| Implementation | Recursive procedure. | Explicit stack and parsing table. |
| Ease of implementation | Easier to implement manually. | More complex due to parsing table construction. |
| Space Complexity | Higher , depends on recursion depth. | Lower, uses explicit stack. |
| Speed | Slower due to recursive calls. | Faster, avoids function call overhead. |
| Error Handling | Complex, involves managing recursive calls. | simplor error detected using parsing table. |
| Productive capability | Uses lookahead and recursion. | Uses single lookahead and parsing table. |
| Back tracking | May require back tracking | No back tracking if grammar is LL(1). |
given grammar
E→TA
A→ +TA|ε
T→FB
B→*FB|ε
F→(E)|id
The FIRST and FOLLOW for the non-terminals are:
| Non-terminal | First | Follows |
| E | {c, id} | {$, )} |
| A | {+, ε } | {$, )} |
| T | {c, id} | {+,$, )} |
| B | {*, ε } | {+,$, )} |
| F | {c, id} | {*,+,$, )} |
Construct SLR parse table for the following grammar
S→E
E→E+T|T
T→T*F|F
F→id
given grammar,
S→E
E→E+T|T
T→T*F|F
F→id
solution
The augmented of given grammar is :
S’→S
S→E
E→E+T|T
T→T*F|F
F→id
I0 = closure(S’→.E) = {S’→.E, E→.E+T, E→.T, T→.F, F→id}
I1 = Goto(I0, E) = closure {S’→E. , E→E.+T} = {S’→E. , E→E.+T}
I2 = Goto(I0, T) = closure {S’→T. , T→T.*F} = {E→T. , T→T.*F}
I3 = Goto(I0, F) = closure {T→F.} = {T→F.}
I4 = Goto(I0, id) = closure {F→id.} = {F→id.}
I5 = Goto(I1, +) = closure {E→E+.T} = {E→E+.T, T→.T*F, T→.F, F→.id}
= Goto (I5 ,F) = closure {T→F.} = {T→F.} same as I3
= Goto (I5 ,id) = closure {F→id.} = {F→id.} same as I4
I6 = Goto(I2, *) = closure {T→T*.F} = {T→T*.F, F→.id}
= Goto (I6 ,id) = closure {F→id.} = {F→id.} same as I4
I7 = Goto(I5, T) = closure {E→E+T.} = {E→E+T.}
I8 = Goto(I6, F) = closure {T→T*F.} = {T→T*F.}
Compute FOLLOW function as,
Follow (S’) = {$}
Follow (S) = Follow (S’) ={$}
Follow (E) = { First(+T) U Follow(S) } = {+, $}
Follow (T) = { First(*F) U First(F) } = {*,+, $}
Follow (F) = {*,+, $}
Drawing DFA


Differentiate between static and dynamic type checking. How can we carry out type checking for the following expression using syntax-directed defination?
S→ id = E
S→ if E then S1
S→ while E do S1
S→ S1; S2
| Features | Static type checking | Dynamic type checking |
| Timing | Performed at compilation. | Performed at runtime. |
| Error Detection | Type error are deteted before execution. | Type error are deteted during execution. |
| Performance | Typically results in faster execution. | May result in slower execution. |
| Safety | Provides higher safety gurantees as errors are caught early. | Provides flexiblity but with possible runtime error. |
| Flexiability | Less flexible, requires explicit type declarations and consistency. | More flexibility types can change and adapt during execution. |
| Language example | C, C++, Java | Python, JavaScript, Ruby |
| Error Handling | Errors are caught and reported at compile time. | Error must be handled or caught during execution. |
given grammar,
S→ id = E
S→ if E then S1
S→ while E do S1
S→ S1; S2
we will define the following attributes:
- E.type : The type expression ‘E’.
- S.type : The type statement ‘S’.
- id.type : The type identifier ‘id’.
SDD for type checking
| Production | Attributes | Semantic Rule |
| S→ id = E | S.type, id.type, E.type | S.type = if (id.type == E.type) then valid else “type error”. |
| S→ if E then S1 | S.type, E.type, S1.type | S.type = if (E.type == ‘boolean’) then S1.type else “type error”. |
| S→ while E do S1 | S.type, E.type, S1.type | S.type = if (E.type == ‘boolean’) then S1.type else “type error”. |
| S→ S1; S2 | S.type, S1.type, S2.type | S.type = if (S1.type == valid and S2.type == valid) then valid else “type error”. |
Discuss about the different factors affecting target code generation.
Target code genration the process of translating an intermediate representation (IR) or high-level language into machine code or a lower – level representation.
Here’s are the different factors affecting target code generation.
- Architecture : Target code generation is influenced by the specific hardware architecture and its features.
- Calling convention : Code generation must adhere to rules for parametor passing , return values , interaperability between modules.
- Optimization goals :Depending on priorities like speed , size , or energy efficiency , the compiler applies different optmization technique , during code generation.
- Intruction selection :Choosing appropriate machine instruction based on the available instrction set , addressing modes , and optimization goals is crucial.
- Data representation :Optimizing memory access patterns , data size , and alignment affects code efficiency.
- Control flow : Handling control flow constructs like loops and conditionals efficiently improves code performance.
Define three address codes. write three address codes for
S → do m = n-p while a <= b
Three-address code is an intermediate representation used in compilors to simplify the process of code generation and optimization. It is a type of intermediate code that uses at most three address (or operands) for each instruction.
For eg: Three address code for expression : a+b*c+d
t1 = b*c
t2 = a+ t1
t3 = t2 + d
given expression :
S → do m = n-p while a <= b
Three address code for given expression:
- m = n-p
- if a < b goto (1)
- if a = b goto (1)
- stop.
Define code optimization. Discuss about any three code optimization techniques with example.
Code optimization is the process of improving the efficiency of code by making it run faster consume less memory, or use fewer resources while preserving the original functionality and output. The goal is to enhance the performance of the code without altering its expected behavior.
Common code optimization technique
a. Constant Folding : In this technique, it involves folding the constants. The expression that contain the operands having constant values at compile time are evaluated. These expression are then replaced with their respective results
Eg: Circumference of circle = $$\frac{{22}}{{7}}×Diameter$$
Here,
- This technique evaluate the expression 22/7 at compile time.
- The expression is then replaced with its result 3.14
- This saves time at run time.
b. Dead code eliminate: In this technique, it involves eliminating the dead code. The statement of the code which either never executes or are unrechable or their output is never used are eliminated.
| Code before optimization | Code after optimized |
| i = o; | i = 0; |
| if (i == 1) | |
| { | |
| a = x+5; | |
| } |
c. Strength reduction:
Here, it involves reducing the strength of expression. This technique replaces the expensive and costly operators with simple and cheaper one’s.
Eg:
| Code before optimization | Code after optimized |
| B = A×2 | B = A +A |
What is activation record? Discuss the different activities performed by caller and callee during procedure call and return.
An activation reocord is a data structure used to manage the execution of produces or functions within a program. Whwn a function is called during execution of program, an activation record is created and stored on the call stack.
The activation recrd contains several pieces of information:
- Return address.
- Parametors.
- Local variables.
- Temporary variables.
- Control link
Different activities performed by caller and callee during procedure call and return are as:
Caller (Calling function)
- Passes argument to the callee.
- Saves the return address.
- Transfers control to the callee.
- Handles the return value after the callee complete execution.
Callee (called function):
1. Executes a prologue:
- Sets up the activation record.
- Allocate space for local variables.
- Sets up the fram pointer.
2. Execute the function code, performing the intended computation.
3. Executes an epilogue before returning:
- Stores return value.
- Restores the frame pointer.
- Deallocates space for local variables.
4. Returns control to the caller, jumping to the saved return address.
5. Returns a value if applicable placing it in the designated return value location.
For more detailed insights on Compiler Design and Construction and additional subjects, stay tuned for regular updates and expanded question bank solutions.